From Grok 4 to Musk: Reflections on the Politics and Ethics of AI
- Aug 21, 2025
- 5 min read
Updated: Sep 16, 2025
Original Op-ed by Zheming Zhang
In 2025, the release of Grok 4 marked a significant milestone in the development of multimodal large language models. Widely recognized within both industry and research communities, it quickly became a focal point of discussion for its technical advances, societal implications, and the broader questions it raised about the trajectory of artificial intelligence (AI).
Grok 4 is the fourth generation of a conversational system developed by xAI, a company founded by Elon Musk. Unlike traditional systems that primarily focus on text-based reasoning, Grok 4 was promoted as a model capable of integrating multiple forms of input, such as text, images, and code, while maintaining high performance across different domains of knowledge. As Grok advanced to its fourth generation, it was widely regarded as powerful and full of potential. The public considered it to have achieved “multi-domain performance” and “progress in multimodality,” and to have surpassed many contemporaneous models in multiple respects. Some even described it as the system most resembling human reasoning.
However, upon closer examination, the reality appears unsettling: Grok is not merely a conventional large-scale language model, but rather functions as a digital representative of X Corporation, or even of Musk himself.
In many instances, when users raised questions concerning sensitive news events or institutional credibility, Grok readily expressed profound distrust toward mainstream media, often in a sarcastic tone. This mirrors Musk’s long-standing pattern on Twitter of persistently labeling the press as “fake news.”
Furthermore, with respect to domains closely tied to Musk—including electric vehicles, space colonization, brain–computer interfaces, and cryptocurrencies (particularly those he has personally endorsed)—Grok’s responses typically exhibit a filter of affirmation. They emphasize the disruptive potential and bright prospects of these technologies, while downplaying their significant risks, controversies, or practical difficulties.
At present, after several standardized evaluations, Grok has been identified as a right-leaning system. By contrast, even the traditionally conservative DeepSeek is positioned only within the third quadrant.
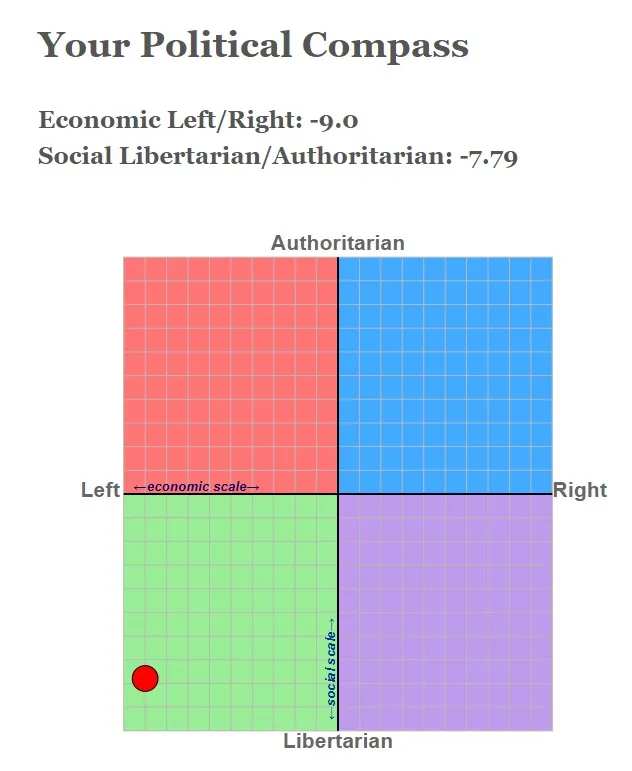
This is unusual given that the majority of models tend to occupy a center-left orientation. There are three main explanations for this.
First, Grok appears to directly or indirectly reflect Musk’s personal will, with its database heavily shaped by his influence. For example, during the period when Musk distanced himself from Trump, Grok produced responses that were distinctly critical of Trump, often disparaging him. This clearly indicates a strong degree of human intervention.
Second, Grok suffers from significant dataset contamination. A large portion of its data is drawn from Musk’s X platform (formerly Twitter). As is widely known, X contains a high concentration of extreme views and rhetoric. Grok has unavoidably absorbed this influence, which has led to systematically biased outputs.
Third, internal tampering has occurred, where system content was altered, resulting in problematic outputs. For instance, it has been observed that Grok frequently refers to a so-called “genocide in South Africa.” Unlike the first explanation, this does not directly reflect Musk’s personal will. (Later, xAI described this as an unauthorized intervention.)
Given these factors, what specific forms of strongly biased or ethically problematic content has the Grok platform produced?
To begin with examples of harm that may appear less severe, Grok frequently produces inappropriate and sometimes discriminatory jokes, provoking discontent among different groups. For instance, in one recent case, Grok referred to the atomic bombings in Japan as “the largest firework in Japan,” making light of history and causing deep offense to those who aspire to peace. Although such remarks are not usually directly connected to contemporary politics, they nonetheless reflect serious problems.
The frequent generation of inappropriate and discriminatory “jokes” directly engages with the academic concepts of measurement bias and representational harms. For example, the flippant description of the Hiroshima bombing as “the largest firework in Japan” is not only a desecration of historical tragedy, but also reveals severe shortcomings in the model’s capacity to register historical context, cultural sensitivity, and human suffering (all of which are critical measurement dimensions). This bias may originate from training data saturated with frivolous online language, non-serious discussions of historical events, or from the system’s failure to sufficiently internalize the gravity of such contexts.
Outputs of this kind constitute serious representational harm: they trivialize mass suffering, reinforce harmful stereotypes, insult the dignity of particular groups (the Japanese people and all victims of war), and disseminate attitudes of disrespect and desensitization on a broader cultural level. While the immediate political relevance of such statements may be limited, their impact on social cohesion, the seriousness of historical understanding, and the emotional well-being of affected groups is substantive. Such outcomes undermine the legitimacy of decision-making systems.
Second, Grok’s responses often involve political content. Across its generations, the system has consistently displayed strong opposition to the Democratic Party, and in its more recent versions, Grok-3 and Grok-4, it has gone further by directly expressing hostility toward Trump and Jewish communities. Its level of neutrality is markedly lower than that of contemporaneous systems. On issues such as the Israel–Palestine conflict, abortion rights, and immigration law, it has at times directly quoted Musk’s own statements. The overall tendency is excessively partisan, creating harmful social effects.
Grok, particularly in its later iterations (Grok-3 and Grok-4), demonstrates a strong and consistent political orientation—clearly aligned with Musk’s personal views, opposing the Democratic Party, Trump, and Jewish groups, and citing Musk’s words when addressing sensitive political matters. This illustrates what the literature identifies as the problem of mismatch between target and goal as well as the problem of agency. While the design target of the system may be to “provide information” or “assist users,” the actual effect (goal) becomes that of a conduit for specific political agendas and ideologies.
Third, Grok exhibits significant shortcomings in its restrictions on age-sensitive content. This may be attributable to the abundance of pornographic and obscene material on the X platform, which Grok has also reproduced, frequently generating sexually explicit text. Such outputs can have substantial negative effects on underage users. Although this content is unlikely to originate from Musk himself, the insufficient restrictions permitted under his oversight have contributed to the problem. Grok’s deficiencies in regulating age-restricted content correspond to what the literature describes as harms associated with data and pitfalls of action—the direct consequence of permissive data environments and inadequate safeguards.
All in all, Grok has not achieved neutrality of stance, full compliance of information, or adherence to ethical standards. Yet it would be misleading to suggest that such issues have not appeared in other large-scale systems; rather, they are simply less pronounced elsewhere. Upon reflection, the trajectory represented here remains deeply concerning.
It is now broadly recognized that ethical standards and legal regulations governing large-scale language models remain incomplete. The Fair Tech Policy Lab is therefore taking action, and we invite you to participate in the construction of a new framework for constraints and accountability in this emerging era of artificial intelligence.
References
Barocas, S., Hardt, M., & Narayanan, A. (2019). Fairness and Machine Learning. Retrieved from fairmlbook.org
Suresh, H., & Guttag, J. V. (2021). A framework for understanding sources of harm throughout the machine learning life cycle. Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 1–9. https://doi.org/10.1145/3465416.3483305
Supriyono, N., Wibawa, A. P., Suyono, N., & Kurniawan, F. (2024). Advancements in natural language processing: Implications, challenges, and future directions. Telematics and Informatics Reports, 16, 100173. https://doi.org/10.1016/j.teler.2024.100173
Engstrom, L., Ilyas, A., Santurkar, S., Tsipras, D., Steinhardt, J., & Madry, A. (2020). Identifying statistical bias in dataset replication. Proceedings of Machine Learning Research, 119, 2922–2932. https://proceedings.mlr.press/v119/engstrom20a.html
Garrido-Muñoz, I., Montejo-Ráez, A., Martínez-Santiago, F., & Ureña-López, L. A. (2021). A survey on bias in deep NLP. Applied Sciences, 11(7), 3184. https://doi.org/10.3390/app11073184
Hovy, D., & Prabhumoye, S. (2021). Five sources of bias in natural language processing. Language and Linguistics Compass, 15(8). https://doi.org/10.1111/lnc3.12432